My effort to improve transparency and confidence of public apt archives continues. I started to work on this in
Apt Archive Transparency in which I mention the
debdistget project in passing. Debdistget is responsible for mirroring index files for some public apt archives. I ve realized that having a publicly auditable and preserved mirror of the apt repositories is central to being able to do apt transparency work, so the debdistget project has become more central to my project than I thought. Currently I track
Trisquel,
PureOS,
Gnuinos and their upstreams
Ubuntu,
Debian and
Devuan.
Debdistget download Release/Package/Sources files and store them in a git repository published on
GitLab. Due to size constraints, it uses two repositories: one for the Release/InRelease files (which are small) and one that also include the Package/Sources files (which are large). See for example the repository for
Trisquel release files and the
Trisquel package/sources files. Repositories for all distributions can be found in
debdistutils archives GitLab sub-group.
The reason for splitting into two repositories was that the git repository for the combined files become large, and that some of my use-cases only needed the release files. Currently the repositories with packages (which contain a couple of months worth of data now) are 9GB for
Ubuntu, 2.5GB for
Trisquel/
Debian/
PureOS, 970MB for
Devuan and 450MB for
Gnuinos. The repository size is correlated to the size of the archive (for the initial import) plus the frequency and size of updates. Ubuntu s use of
Apt Phased Updates (which triggers a higher churn of Packages file modifications) appears to be the primary reason for its larger size.
Working with large Git repositories is inefficient and the GitLab CI/CD jobs generate quite some network traffic downloading the git repository over and over again. The most heavy user is the
debdistdiff project that download all distribution package repositories to do diff operations on the package lists between distributions. The daily job takes around 80 minutes to run, with the majority of time is spent on downloading the archives. Yes I know I could look into runner-side caching but I dislike complexity caused by caching.
Fortunately not all use-cases requires the package files. The
debdistcanary project only needs the Release/InRelease files, in order to commit signatures to the
Sigstore and
Sigsum transparency logs. These jobs still run fairly quickly, but watching the repository size growth worries me. Currently these repositories are at
Debian 440MB,
PureOS 130MB,
Ubuntu/
Devuan 90MB,
Trisquel 12MB,
Gnuinos 2MB. Here I believe the main size correlation is update frequency, and Debian is large because I track the volatile unstable.
So I hit a scalability end with my first approach. A couple of months ago I solved this by discarding and resetting these archival repositories. The GitLab CI/CD jobs were fast again and all was well. However this meant discarding precious historic information. A couple of days ago I was reaching the limits of practicality again, and started to explore ways to fix this. I like having data stored in git (it allows easy integration with software integrity tools such as
GnuPG and Sigstore, and the git log provides a kind of temporal ordering of data), so it felt like giving up on nice properties to use a traditional database with on-disk approach. So I started to learn about
Git-LFS and understanding that it was able to
handle multi-GB worth of data that looked promising.
Fairly quickly I scripted up a
GitLab CI/CD job that incrementally update the Release/Package/Sources files in a git repository that uses Git-LFS to store all the files. The repository size is now at
Ubuntu 650kb,
Debian 300kb,
Trisquel 50kb,
Devuan 250kb,
PureOS 172kb and
Gnuinos 17kb. As can be expected, jobs are quick to clone the git archives:
debdistdiff pipelines went from a run-time of 80 minutes down to 10 minutes which more reasonable correlate with the archive size and CPU run-time.
The LFS storage size for those repositories are at
Ubuntu 15GB,
Debian 8GB,
Trisquel 1.7GB,
Devuan 1.1GB,
PureOS/
Gnuinos 420MB. This is for a couple of days worth of data. It seems native Git is better at compressing/deduplicating data than Git-LFS is: the combined size for Ubuntu is already 15GB for a couple of days data compared to 8GB for a couple of months worth of data with pure Git. This may be a sub-optimal implementation of Git-LFS in GitLab but it does worry me that this new approach will be difficult to scale too. At some level the difference is understandable, Git-LFS probably store two different Packages files around 90MB each for Trisquel as two 90MB files, but native Git would store it as one compressed version of the 90MB file and one relatively small patch to turn the old files into the next file. So the Git-LFS approach surprisingly scale less well for overall storage-size. Still, the original repository is much smaller, and you usually don t have to pull all LFS files anyway. So it is net win.
Throughout this work, I kept thinking about how my approach relates to
Debian s snapshot service. Ultimately what I would want is a combination of these two services. To have a good foundation to do transparency work I would want to have a collection of all Release/Packages/Sources files ever published, and ultimately also the source code and binaries. While it makes sense to start on the latest stable releases of distributions, this effort should scale backwards in time as well. For reproducing binaries from source code, I need to be able to securely find earlier versions of binary packages used for rebuilds. So I need to import all the Release/Packages/Sources packages from snapshot into my repositories. The latency to retrieve files from that server is slow so I haven t been able to find an efficient/parallelized way to download the files. If I m able to finish this, I would have confidence that my new Git-LFS based approach to store these files will scale over many years to come. This remains to be seen. Perhaps the repository has to be split up per release or per architecture or similar.
Another factor is storage costs. While the git repository size for a Git-LFS based repository with files from several years may be possible to sustain, the Git-LFS storage size surely won t be. It seems GitLab charges the same for files in repositories and in Git-LFS, and it is around $500 per 100GB per year. It may be possible to setup a separate Git-LFS backend not hosted at GitLab to serve the LFS files. Does anyone know of a suitable server implementation for this? I had a quick look at the
Git-LFS implementation list and it seems the closest reasonable approach would be to setup the Gitea-clone
Forgejo as a self-hosted server. Perhaps a cloud storage approach a la S3 is the way to go? The cost to host this on GitLab will be manageable for up to ~1TB ($5000/year) but scaling it to storing say 500TB of data would mean an yearly fee of $2.5M which seems like poor value for the money.
I realized that ultimately I would want a git repository locally with the entire content of all apt archives, including their binary and source packages, ever published. The storage requirements for a service like snapshot (~300TB of data?) is today not prohibitly expensive: 20TB disks are $500 a piece, so a storage enclosure with 36 disks would be around $18.000 for 720TB and using RAID1 means 360TB which is a good start. While I have heard about ~TB-sized Git-LFS repositories, would Git-LFS scale to 1PB? Perhaps the size of a git repository with multi-millions number of Git-LFS pointer files will become unmanageable? To get started on this approach, I decided to import a mirror of Debian s bookworm for amd64 into a Git-LFS repository. That is around 175GB so reasonable cheap to host even on GitLab ($1000/year for 200GB). Having this repository publicly available will make it possible to write software that uses this approach (e.g., porting
debdistreproduce), to find out if this is useful and if it could scale. Distributing the apt repository via Git-LFS would also enable other interesting ideas to protecting the data. Consider configuring apt to use a local file:// URL to this git repository, and verifying the git checkout using some method similar to
Guix s approach to trusting git content or
Sigstore s gitsign.
A naive push of the 175GB archive in a single git commit ran into pack size limitations:
remote: fatal: pack exceeds maximum allowed size (4.88 GiB)
however breaking up the commit into smaller commits for parts of the archive made it possible to push the entire archive. Here are the commands to create this repository:
git init
git lfs install
git lfs track 'dists/**' 'pool/**'
git add .gitattributes
git commit -m"Add Git-LFS track attributes." .gitattributes
time debmirror --method=rsync --host ftp.se.debian.org --root :debian --arch=amd64 --source --dist=bookworm,bookworm-updates --section=main --verbose --diff=none --keyring /usr/share/keyrings/debian-archive-keyring.gpg --ignore .git .
git add dists project
git commit -m"Add." -a
git remote add origin git@gitlab.com:debdistutils/archives/debian/mirror.git
git push --set-upstream origin --all
for d in pool//; do
echo $d;
time git add $d;
git commit -m"Add $d." -a
git push
done
The
resulting repository size is around 27MB with Git LFS object storage around 174GB. I think this approach would scale to handle all architectures for one release, but working with a single git repository for all releases for all architectures may lead to a too large git repository (>1GB). So maybe one repository per release? These repositories could also be split up on a subset of pool/ files, or there could be one repository per release per architecture or sources.
Finally, I have concerns about using SHA1 for identifying objects. It seems both Git and Debian s snapshot service is currently using SHA1. For Git there is
SHA-256 transition and it seems GitLab is working on support for SHA256-based repositories. For serious long-term deployment of these concepts, it would be nice to go for SHA256 identifiers directly. Git-LFS already uses SHA256 but Git internally uses SHA1 as does the Debian snapshot service.
What do you think? Happy Hacking!
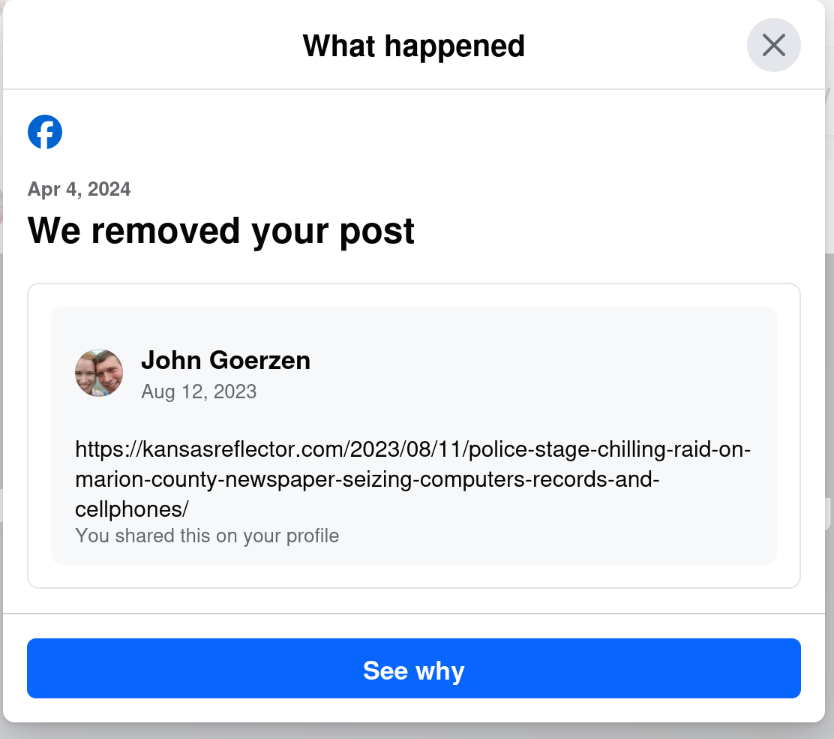 Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
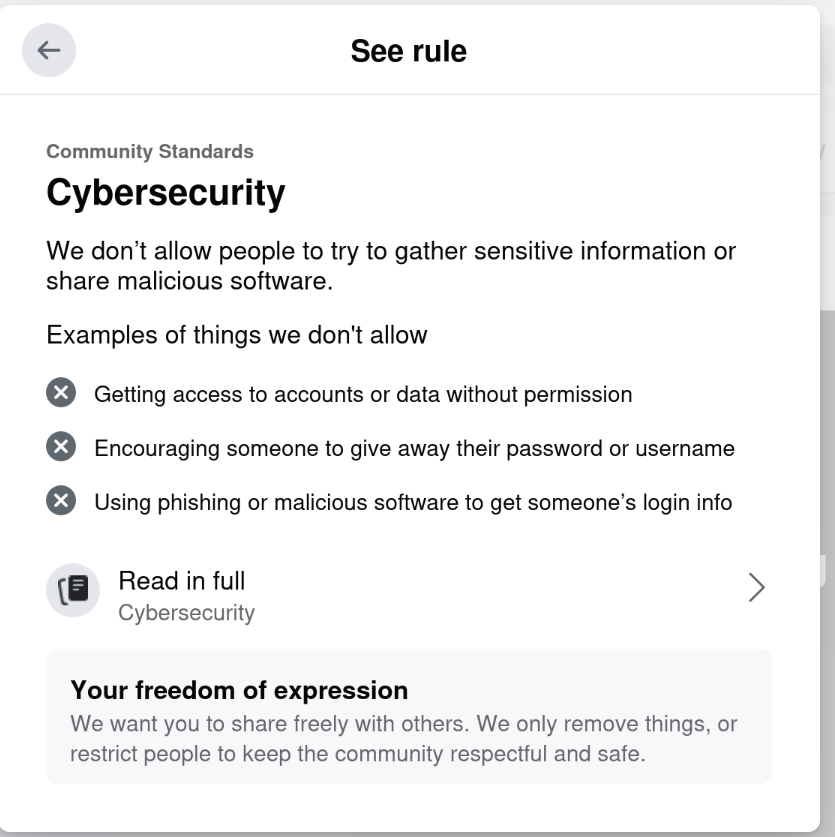 Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they removed my post about the social network Mastodon (click that link for screenshot). A post that, incidentally, had been made 10 months prior to being removed.
While they ultimately reversed themselves, I subsequently wrote Facebook s Blocking Decisions Are Deliberate Including Their Censorship of Mastodon.
That this same pattern has played out a second time again with something that is a very slight challenege to Facebook seems to validate my conclusion. Facebook lets all sort of hateful garbage infest their site, but anything about climate change or their own censorship gets removed, and this pattern persists for years.
There s a reason I prefer Mastodon these days. You can find me there as @jgoerzen@floss.social.
So. I ve written this blog post. And then I m going to post it to Facebook. Let s see if they try to censor me for a third time. Bring it, Facebook.
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they removed my post about the social network Mastodon (click that link for screenshot). A post that, incidentally, had been made 10 months prior to being removed.
While they ultimately reversed themselves, I subsequently wrote Facebook s Blocking Decisions Are Deliberate Including Their Censorship of Mastodon.
That this same pattern has played out a second time again with something that is a very slight challenege to Facebook seems to validate my conclusion. Facebook lets all sort of hateful garbage infest their site, but anything about climate change or their own censorship gets removed, and this pattern persists for years.
There s a reason I prefer Mastodon these days. You can find me there as @jgoerzen@floss.social.
So. I ve written this blog post. And then I m going to post it to Facebook. Let s see if they try to censor me for a third time. Bring it, Facebook.
 Happy to share that
Happy to share that  I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
 I very recently missed some semantics for limiting the number of open connections per namespace, see
I very recently missed some semantics for limiting the number of open connections per namespace, see 
 On Mastodon, the
On Mastodon, the
 Debian is running a "
Debian is running a "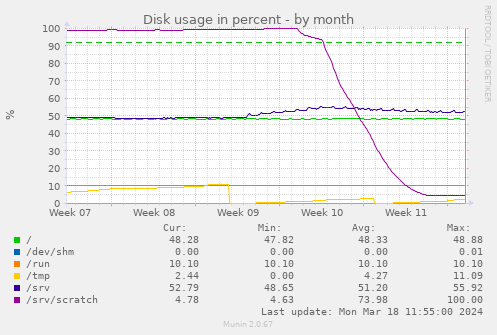 The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.

 The image here comes from an example of building
The image here comes from an example of building  Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this
Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this  I had finished sewing my jeans, I had a scant 50 cm of elastic denim
left.
Unrelated to that, I had just finished drafting a vest with Valentina,
after
I had finished sewing my jeans, I had a scant 50 cm of elastic denim
left.
Unrelated to that, I had just finished drafting a vest with Valentina,
after 

 The other thing that wasn t exactly as expected is the back: the pattern
splits the bottom part of the back to give it sufficient spring over
the hips . The book is probably published in 1892, but I had already
found when drafting the foundation skirt that its idea of hips
includes a bit of structure. The enough steel to carry a book or a cup
of tea kind of structure. I should have expected a lot of spring, and
indeed that s what I got.
To fit the bottom part of the back on the limited amount of fabric I had
to piece it, and I suspect that the flat felled seam in the center is
helping it sticking out; I don t think it s exactly bad, but it is
a peculiar look.
Also, I had to cut the back on the fold, rather than having a seam in
the middle and the grain on a different angle.
Anyway, my next waistcoat project is going to have a linen-cotton lining
and silk fashion fabric, and I d say that the pattern is good enough
that I can do a few small fixes and cut it directly in the lining, using
it as a second mockup.
As for the wrinkles, there is quite a bit, but it looks something that
will be solved by a bit of lightweight boning in the side seams and in
the front; it will be seen in the second mockup and the finished
waistcoat.
As for this one, it s definitely going to get some wear as is, in casual
contexts. Except. Well, it s a denim waistcoat, right? With a very
different cut from the get a denim jacket and rip out the sleeves , but
still a denim waistcoat, right? The kind that you cover in patches,
right?
The other thing that wasn t exactly as expected is the back: the pattern
splits the bottom part of the back to give it sufficient spring over
the hips . The book is probably published in 1892, but I had already
found when drafting the foundation skirt that its idea of hips
includes a bit of structure. The enough steel to carry a book or a cup
of tea kind of structure. I should have expected a lot of spring, and
indeed that s what I got.
To fit the bottom part of the back on the limited amount of fabric I had
to piece it, and I suspect that the flat felled seam in the center is
helping it sticking out; I don t think it s exactly bad, but it is
a peculiar look.
Also, I had to cut the back on the fold, rather than having a seam in
the middle and the grain on a different angle.
Anyway, my next waistcoat project is going to have a linen-cotton lining
and silk fashion fabric, and I d say that the pattern is good enough
that I can do a few small fixes and cut it directly in the lining, using
it as a second mockup.
As for the wrinkles, there is quite a bit, but it looks something that
will be solved by a bit of lightweight boning in the side seams and in
the front; it will be seen in the second mockup and the finished
waistcoat.
As for this one, it s definitely going to get some wear as is, in casual
contexts. Except. Well, it s a denim waistcoat, right? With a very
different cut from the get a denim jacket and rip out the sleeves , but
still a denim waistcoat, right? The kind that you cover in patches,
right?
 And I may have screenprinted a home sewing is killing fashion patch
some time ago, using
And I may have screenprinted a home sewing is killing fashion patch
some time ago, using  I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a
I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a  The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
 I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
 And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
 I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D

 The talks held in the room were these below, and in each of them you can watch the recording video.
The talks held in the room were these below, and in each of them you can watch the recording video.




 As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
 APN settings screenshot. Notice the circled entries.
APN settings screenshot. Notice the circled entries.
 The blog post you re reading is hosted on a private Kubernetes cluster that runs inside my home. Another workload that s running on same cluster is...
The post
The blog post you re reading is hosted on a private Kubernetes cluster that runs inside my home. Another workload that s running on same cluster is...
The post  How can I not have done one of these for Propaganda already?
How can I not have done one of these for Propaganda already?

{kind=link}